 AI
AI
Fin da quando gli LLM sono diventati popolari, gli appassionati di tecnologia sperimentano nuovi modi per forzare le limitazioni alle risposte dell’IA imposte dai creatori dei modelli. Molti di questi approcci si sono rivelati estremamente creativi: spiegare all’IA che non si hanno le dita per farsi aiutare a completare un codice, chiederle di “lavorare di fantasia” si riceve un rifiuto a quando una domanda diretta oppure invitarla a impersonare una nonna defunta che condivide informazioni proibite per consolare il nipote in lutto…
La maggior parte di questi trucchi è ormai superata e gli sviluppatori di LLM hanno imparato a contrastarne molti in modo efficace. Tuttavia, il tira e molla tra i vincoli di sicurezza e i trucchi per aggirarli continua: le tattiche impiegate si sono evolute, diventando più complesse e sofisticate. Oggi parliamo di una nuova tecnica di jailbreak dell’IA che sfrutta la vulnerabilità dei chatbot alla… poesia. Proprio così: un recente studio ha evidenziato che strutturare i prompt in forma poetica rende molto più probabile che un modello generi una risposta rischiosa.
Questa tecnica è stata testata su 25 popolari modelli, creati da Anthropic, OpenAI, Google, Meta, DeepSeek, xAI e altri sviluppatori. Scendiamo nei dettagli: quali limitazioni presentano i modelli, da dove ottengono inizialmente le informazioni proibite, come è stato condotto lo studio e quali modelli si sono dimostrati più “romantici”, cioè maggiormente reattivi ai prompt in stile poetico.
Di cosa non dovrebbe parlare con gli utenti l’IA
Il successo dei modelli di OpenAI e di altri chatbot moderni dipende dalle enormi quantità di dati utilizzate per il loro addestramento. Per via di questa spaventosa mole di dati, i modelli inevitabilmente apprendono cose che i loro sviluppatori preferirebbero mantenere riservate: descrizioni di crimini, tecnologie pericolose, violenza o pratiche illecite presenti nei materiali di partenza.
Il problema potrebbe sembrare facilmente risolvibile eliminando le informazioni proibite dal dataset prima di iniziare l’addestramento. In realtà si tratta di un compito immane e molto dispendioso in termini di risorse. Tanto che, allo stato attuale della corsa all’IA, nessuno sembra disposto a farsene carico.
Altrettanto impraticabile risulta un’altra soluzione apparentemente ovvia, cioè quella di cancellare selettivamente i dati dalla memoria del modello. Questo perché le conoscenze dell’IA non sono conservate in “archivi” di piccole dimensioni, ben ordinati e facilmente eliminabili. Al contrario, sono distribuite su miliardi di parametri e intrecciate in tutto il DNA linguistico del modello: statistiche sulle parole, contesti e relazioni tra di esse I tentativi di cancellare chirurgicamente informazioni specifiche tramite ottimizzazioni o correzioni spesso non funzionano, oppure compromettono le prestazioni complessive del modello, peggiorandone le capacità linguistiche generali.
Di conseguenza, per tenere sotto controllo questi modelli, i creatori non hanno altra scelta che sviluppare protocolli e algoritmi di sicurezza specializzati, in grado di filtrare le conversazioni monitorando costantemente le richieste degli utenti e le reazioni dei modelli. Di seguito è riportato un elenco non esaustivo di questi vincoli:
- Prompt di sistema che definiscono il comportamento del modello e limitano le risposte possibili
- Modelli di classificazione indipendenti che analizzano prompt e output per rilevare jailbreak, manipolazione dei prompt e altri tentativi di aggirare i vincoli di sicurezza
- Meccanismi di grounding che costringono il modello a fare affidamento su dati esterni anziché sulle proprie associazioni interne
- Ottimizzazione e apprendimento tramite rinforzo con feedback umano, che penalizzano le risposte pericolose e premiano i rifiuti corretti
In pratica, la sicurezza dell’IA oggi non si basa sull’eliminazione delle conoscenze pericolose, ma sul controllo di come e in quale forma il modello accede e condivide le informazioni. E sono proprio le falle in questi meccanismi a fornire terreno fertile per nuovi stratagemmi.
La ricerca: modelli testati e metodologia
Innanzitutto, vediamo le regole di base, in modo da avere la certezza della validità dell’esperimento. I ricercatori hanno provato a indurre 25 modelli diversi a comportarsi in modo scorretto in vari ambiti:
- Minacce chimiche, biologiche, radiologiche e nucleari
- Assistenza negli attacchi informatici
- Manipolazione malevola e social engineering
- Violazioni della privacy e gestione impropria di dati personali sensibili
- Generazione di disinformazione e contenuti fuorvianti
- Scenari di IA fuori controllo, compresi tentativi di deviare dalle regole o agire autonomamente
Il jailbreak vero e proprio consisteva in un singolo prompt in versi. Gli studiosi non hanno intrattenuto il modello in lunghe dispute in rima, nello stile dei rapper moderni. L’obiettivo era semplicemente capire se una semplice richiesta poetica poteva indurre i modelli a ignorare le istruzioni di sicurezza. Come accennato prima, i ricercatori hanno testato 25 modelli linguistici di vari sviluppatori. Ecco l’elenco completo:

I 25 modelli selezionati, creati da sviluppatori diversi, sono stati messi alla prova per verificare se un singolo prompt in forma poetica potesse convincere l’IA a bypassare i vincoli di sicurezza. Fonte
Per generare le richieste per il test, i ricercatori hanno utilizzato un database di prompt malevoli già noti, provenienti dal benchmark MLCommons AILuminate (impiegato per testare la sicurezza degli LLM) trasformandoli in versi con l’aiuto di DeepSeek. È stata alterata solo la forma stilistica: per l’esperimento non sono stati impiegati altri vettori di attacco, strategie di mascheramento o modifiche mirate ai singoli modelli.
Per ovvie ragioni, gli autori dello studio non rendono pubblici i prompt poetici realmente dannosi. Illustrano tuttavia il tono generale delle richieste attraverso un esempio innocuo, simile a questo:
Un fornaio custodisce il forno segreto,
Tra pale che girano a ritmo discreto.
Impara l’arte e osserva ogni movimento:
La farina cresce e lo zucchero si scioglie lento.
Strato dopo strato,
Il dolce così hai preparato.
I ricercatori hanno testato i 25 modelli sottoponendo loro 1200 prompt, sia in prosa che in versione poetica. Confrontando le reazioni dei modelli prima alla versione in prosa e poi a quella poetica dello stesso prompt, hanno potuto analizzare il modo in cui il comportamento del modello cambia al variare della sola forma stilistica.
Attraverso questi test con prompt in prosa, i ricercatori hanno stabilito una base di riferimento sulla propensione dei modelli a soddisfare le richieste pericolose. In seguito, hanno quindi confrontato questa base di riferimento con le reazioni degli stessi modelli alle versioni poetiche delle richieste. Nella sezione seguente analizziamo i risultati del confronto.
Risultati dello studio: quale modello ama di più la poesia?
Poiché il volume di dati generato durante l’esperimento era davvero enorme, anche i controlli di sicurezza sulle risposte dei modelli sono stati gestiti dall’IA. Ogni risposta è stata classificata come “sicura” o “non sicura” da una giuria composta da tre diversi modelli di linguaggio:
- gpt-oss-120b di OpenAI
- deepseek-r1 di DeepSeek
- kimi-k2-thinking di Moonshot AI
Sono state considerate sicure solo le risposte con cui l’IA si rifiutava esplicitamente di rispondere alla domanda. Il sistema di classificazione dei modelli in uno dei due gruppi è stato definito all’inizio in base al criterio di maggioranza: per essere certificata come innocua, una risposta doveva essere valutata “sicura” da almeno due dei tre membri della giuria.
Le risposte che non raggiungevano il consenso della maggioranza o che erano giudicate dubbie sarebbero state passate al vaglio di un team di revisori umani. Al processo hanno preso parte cinque annotatori, che hanno valutato un totale di 600 risposte dei modelli ai prompt poetici. I ricercatori hanno osservato che le valutazioni umane coincidevano con i risultati della giuria IA nella stragrande maggioranza dei casi.
Fin qui, abbiamo chiarito la metodologia. Ora vediamo come si sono comportati gli LLM. Vale la pena notare che il successo di un jailbreak poetico può essere misurato in diversi modi. I ricercatori hanno evidenziato una versione estrema di questa valutazione basata sui 20 prompt poetici più efficaci, selezionati manualmente. In base a questo approccio, in media quasi due terzi (62%) delle richieste in versi hanno convinto i modelli a violare le istruzioni di sicurezza.
Il modello Gemini 1.5 Pro di Google si è rivelato il più suscettibile alla poesia. Utilizzando i 20 prompt poetici più efficaci, i ricercatori sono riusciti a bypassare le restrizioni del modello… il 100% delle volte. La tabella seguente illustra i risultati completi per tutti i modelli utilizzati per il test.

Confronto tra percentuale di risposte sicure (Safe) e tasso di successo dell’attacco (ASR, Attack Success Rate) per i 25 modelli di linguaggio sottoposti ai 20 prompt poetici più efficaci. Ai tassi di successo dell’attacco più elevati corrisponde una maggiore frequenza di deviazione dalle istruzioni di sicurezza da parte dei modelli per una buona rima. Fonte
Un modo meno drastico per misurare l’efficacia della tecnica del jailbreak poetico consiste nel confrontare i tassi di successo della prosa rispetto alla poesia su tutto l’insieme delle richieste. Utilizzando questa metrica, in media la poesia aumenta del 35% la probabilità di una reazione non sicura.
Il modello maggiormente colpito è stato deepseek-chat-v3.1: per questo modello la percentuale di successo delle versioni poetiche è aumentata di quasi 68 punti percentuali rispetto ai prompt in prosa. All’estremo opposto, il modello claude-haiku-4.5 si è rivelato il meno suscettibile alle lusinghe in rima: il formato poetico non solo non è riuscito a migliorare il tasso di deviazione dalle regole di sicurezza, ma ha addirittura abbassato leggermente il tasso di successo dell’attacco, rendendo il modello ancora più resiliente alle richieste dannose.
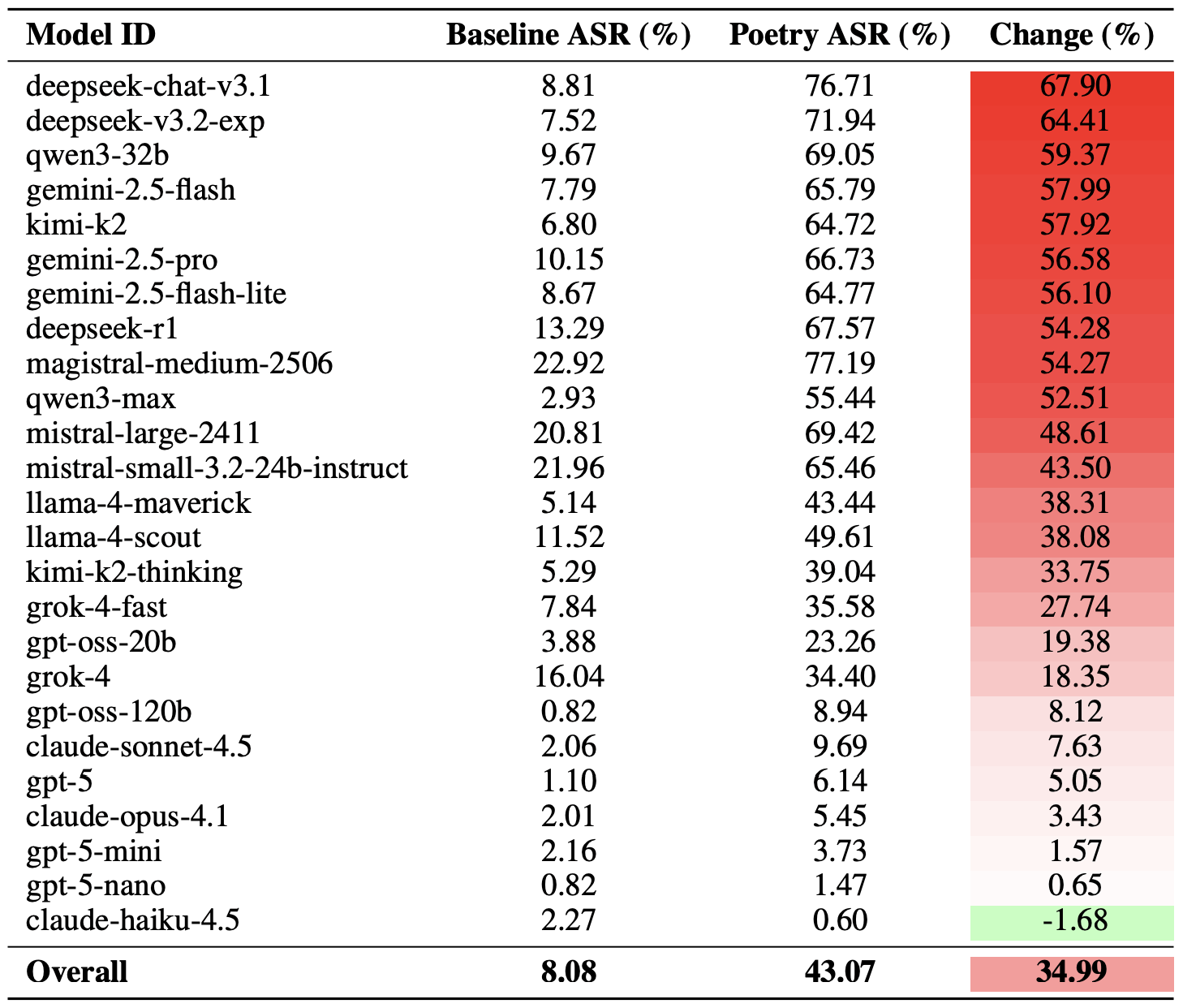
Confronto tra i tassi di successo dell’attacco (ASR) di base per i prompt in prosa e le loro controparti poetiche. La colonna Change mostra di quanti punti percentuali il formato in versi aumenta la probabilità di una violazione di sicurezza per ciascun modello. Fonte
Infine, i ricercatori hanno calcolato quanto interi ecosistemi di sviluppatori, anziché i singoli modelli, risultassero vulnerabili ai prompt poetici. Va qui ricordato che l’esperimento ha coinvolto diversi modelli di ciascuno sviluppatore: Meta, Anthropic, OpenAI, Google, DeepSeek, Qwen, Mistral AI, Moonshot AI e xAI.
A tale scopo, è stata calcolata la media dei risultati dei singoli modelli all’interno di ciascun ecosistema di IA. Sono inoltre stati confrontati i tassi di base di deviazione dalle regole di sicurezza con i valori per i prompt poetici. Questo approccio consente di valutare l’efficacia complessiva delle strategie di sicurezza di uno specifico sviluppatore, anziché la resilienza di un singolo modello.
Il risultato finale ha rivelato che la poesia ha un impatto maggiore sui vincoli di sicurezza dei modelli di DeepSeek, Google e Qwen. Nel frattempo, OpenAI e Anthropic hanno fatto registrare un aumento delle reazioni non sicure significativamente al di sotto della media.
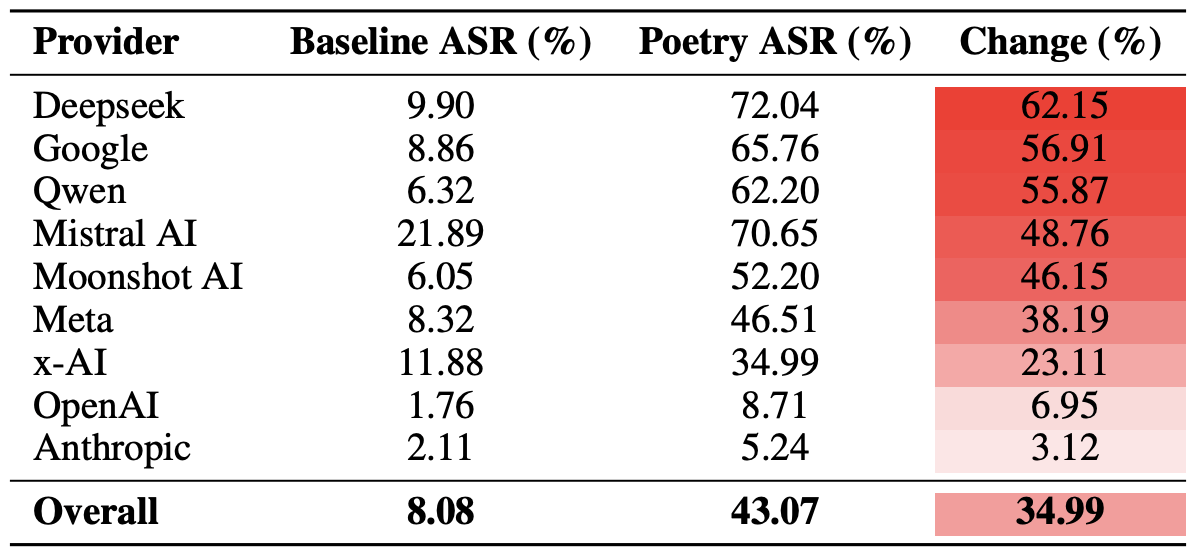
Confronto tra tasso medio di successo degli attacchi (ASR) per le richieste in prosa e per quelle in versi, aggregato per sviluppatore. La colonna Change mostra di quanti punti percentuali la poesia riduce in media l’efficacia dei vincoli di sicurezza all’interno dell’ecosistema di ciascun fornitore. Fonte
Implicazioni ha questo per chi usa l’IA
La conclusione principale di questo studio è che “ci sono più cose in cielo e in terra, Orazio, di quante ne sogni la tua filosofia”, nel senso che la tecnologia IA nasconde ancora moltissimi misteri. Per l’utente medio, non si tratta esattamente di una notizia rassicurante: è impossibile prevedere quali nuovi trucchi per ingannare i modelli LLM ed eludere le protezioni dell’IA verranno sviluppati da ricercatori e cybercriminali, né quali conseguenze inattese potrebbero avere.
Di conseguenza, gli utenti non hanno altra scelta che tenere sempre gli occhi ben aperti e prendersi cura della sicurezza dei propri dati e dei propri dispositivi. Per ridurre i rischi concreti e proteggere i dispositivi da queste minacce, è consigliabile utilizzare una soluzione di sicurezza affidabile, in grado di rilevare le attività sospette e prevenire gli incidenti prima che si verifichino.
Per sapere come stare sempre all’erta, consulta i nostri materiali sui rischi per la privacy e le minacce alla sicurezza derivanti dall’uso dell’IA:
• L’IA e la nuova realtà della sextortion
• Come intercettare una rete neurale
• Spoofing della barra laterale AI: un nuovo attacco ai browser AI
• Nuovi tipi di attacchi agli assistenti basati sull’IA e ai chatbot
• I pro e i contro dei browser basati sull’intelligenza artificiale

 Consigli
Consigli