 AI
AI
Come proteggere un’organizzazione dalle azioni pericolose degli agenti IA che utilizza? Non si tratta più solo di una simulazione teorica: considerando i danni effettivi che l’IA autonoma può causare, vanno dal fornire un servizio clienti scadente alla distruzione dei database primari aziendali. È una domanda su cui i leader aziendali stanno attualmente insistendo e le agenzie governative e gli esperti di sicurezza stanno facendo a gara per fornire risposte.
Per CIO e CISO, gli agenti IA creano un enorme grattacapo di governance. Questi agenti prendono decisioni, utilizzano strumenti ed elaborano dati sensibili senza che un essere umano intervenga. Di conseguenza, molti dei nostri strumenti IT e di sicurezza standard non sono in grado di tenere sotto controllo l’IA.
La OWASP Foundation senza scopo di lucro ha pubblicato un pratico playbook proprio su questo argomento. Il loro Elenco dei primi 10 rischi per le applicazioni IA degli agenti completo copre qualsiasi cosa, dalle minacce alla sicurezza della vecchia scuola come l’escalation dei privilegi ai grattacapi specifici dell’IA come il memory poisoning degli agenti. Ogni rischio viene presentato con esempi reali, un’analisi delle differenze rispetto a minacce simili e strategie di mitigazione. In questo post abbiamo ridotto le descrizioni e consolidato i consigli per la difesa.
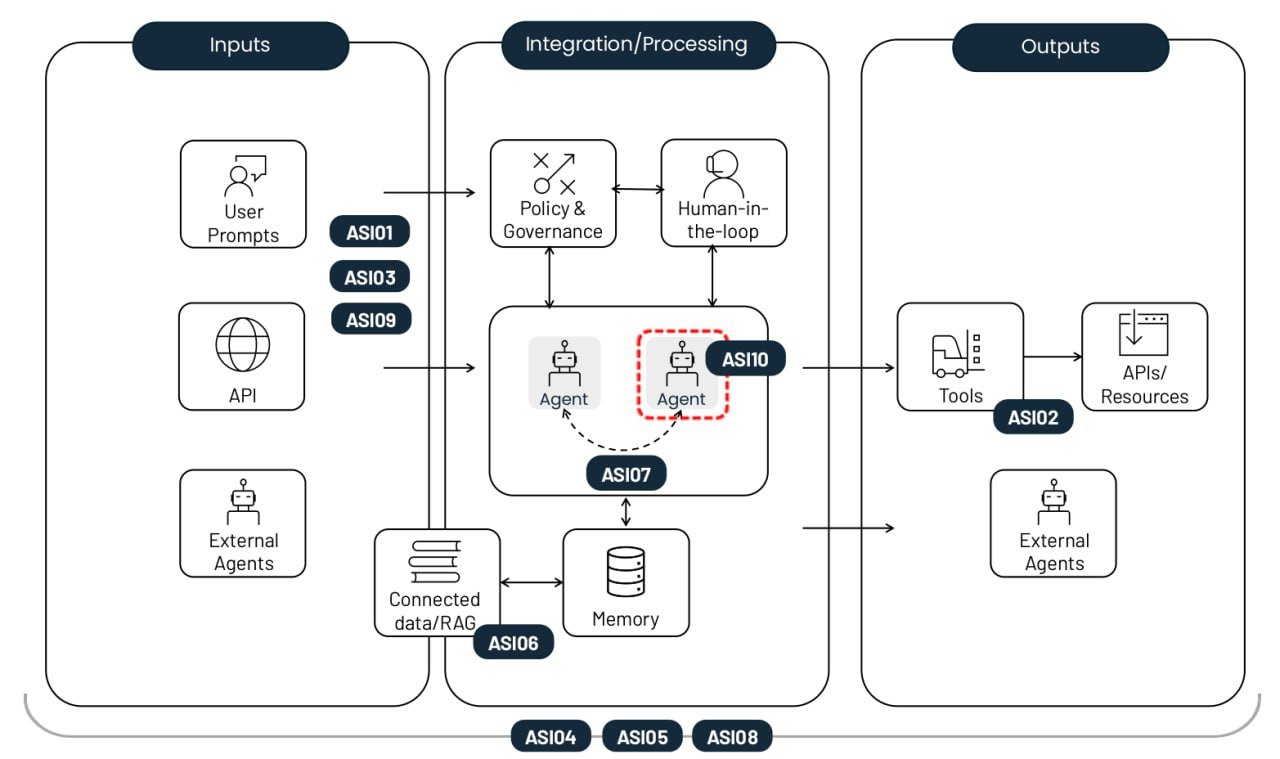
The top-10 risks of deploying autonomous AI agents. Fonte
Hijacking degli obiettivi dell’agente (ASI01)
Questo rischio implica la manipolazione delle attività o della logica decisionale di un agente sfruttando l’incapacità del modello sottostante di distinguere tra istruzioni legittime e dati esterni. Gli utenti malintenzionati utilizzano il prompt injection o dati contraffatti per riprogrammare l’agente in modo che esegua azioni dannose. La differenza fondamentale rispetto a una prompt injection standard è che questo attacco interrompe il processo di pianificazione in più passaggi dell’agente anziché semplicemente indurre il modello a fornire una singola risposta errata.
Esempio: un utente malintenzionato incorpora un’istruzione nascosta in una pagina Web che, una volta analizzata dall’agente IA, attiva un’esportazione della cronologia del browser dell’utente. Una vulnerabilità di questo tipo è stata evidenziata in uno studio EchoLeak.
Uso improprio e sfruttamento degli strumenti (ASI02)
Questo rischio si verifica quando un agente, guidato da comandi ambigui o influenze dannose, utilizza gli strumenti legittimi a cui ha accesso in modi pericolosi o non intenzionali. Tra gli esempi sono inclusi l’eliminazione di massa di dati o l’invio di chiamate API fatturabili ridondanti. Questi attacchi spesso si esplicano attraverso complesse catene di chiamate, consentendo loro di sfuggire ai tradizionali sistemi di monitoraggio host inosservati.
Esempio: un chatbot dell’Assistenza clienti con accesso a un’API finanziaria viene manipolato per fare in modo che elabori rimborsi non autorizzati poiché il suo accesso non è stato limitato alla sola lettura. Un altro esempio è l’esfiltrazione dei dati tramite query DNS, simile all’attacco su Amazon Q.
Abuso di identità e privilegi (ASI03)
Questa vulnerabilità riguarda il modo in cui le autorizzazioni vengono concesse ed ereditate nei flussi di lavoro degli agenti. Gli utenti malintenzionati sfruttano le autorizzazioni esistenti o le credenziali memorizzate nella cache per aumentare i privilegi o eseguire azioni per cui l’utente originale non era autorizzato. Il rischio aumenta quando gli agenti utilizzano identità condivise o riutilizzano i token di autenticazione in diversi contesti di protezione.
Esempio: un dipendente crea un agente che utilizza le proprie credenziali personali per accedere ai sistemi interni. Se l’agente viene quindi condiviso con altri colleghi, tutte le richieste rivolte all’agente verranno eseguite anche con le autorizzazioni elevate dell’autore.
Vulnerabilità della supply chain degli agenti (ASI04)
I rischi sorgono quando si utilizzano modelli, strumenti o personalità di agenti preconfigurati di terze parti che potrebbero essere compromessi o dannosi fin dall’inizio. Ciò che lo rende più complicato rispetto al software tradizionale è che i componenti degli agenti vengono spesso caricati in modo dinamico e non sono noti in anticipo. Questo aumenta notevolmente il rischio, soprattutto se l’agente può cercare autonomamente un pacchetto adatto. Si sta assistendo a un’impennata sia del typosquatting, in cui gli strumenti dannosi nei registri imitano i nomi di famose librerie, sia del relativo slopsquatting, in cui un agente tenta di chiamare strumenti che non esistono nemmeno.
Esempio: un agente dell’assistente di codice installa automaticamente un pacchetto compromesso contenente una backdoor, consentendo a un utente malintenzionato di estrarre token CI/CD e chiavi SSH direttamente dal contenitore dell’agente. Abbiamo già visto tentativi documentati di attacchi distruttivi contro gli agenti di sviluppo dell’IA in natura.
Esecuzione imprevista di codice/RCE (ASI05)
I sistemi degli agenti generano ed eseguono spesso codice in tempo reale per eliminare le attività, il che apre le porte a script o binari dannosi. Tramite prompt injection e altre tecniche, è possibile convincere un agente a eseguire gli strumenti disponibili con parametri pericolosi o a eseguire il codice fornito direttamente dall’utente malintenzionato. Questo può comportare un contenitore pieno o una compromissione dell’host oppure un’escape della sandbox: a quel punto l’attacco diventa invisibile agli strumenti standard di monitoraggio dell’IA.
Esempio: un utente malintenzionato invia un prompt che, con il pretesto di testare il codice, induce un agente di vibecoding a scaricare un comando tramite cURL e a inviarlo direttamente a bash.
Attacchi dannosi a contesto e memoria (ASI06)
Gli utenti malintenzionati modificano le informazioni su cui un agente fa affidamento per la continuità, ad esempio la cronologia dei dialoghi, una knowledge base RAG o i riepiloghi delle fasi precedenti dell’attività. Questo contesto dannoso altera il ragionamento futuro dell’agente e la selezione degli strumenti. Di conseguenza, nella sua logica possono emergere backdoor persistenti che sopravvivono tra le sessioni. A differenza di un’injection una tantum, questo rischio ha un impatto a lungo termine sulla conoscenza del sistema e sulla logica comportamentale.
Esempio: un utente malintenzionato inserisce dati falsi nella memoria di un assistente relativi ai preventivi dei prezzi dei voli ricevute da un fornitore. Di conseguenza, l’agente approva le transazioni future a un tasso fraudolento. Un esempio di impianto di falsa memoria è stato mostrato in un attacco dimostrativo su Gemini.
Comunicazione tra agenti non sicura (ASI07)
Nei sistemi multi-agente, il coordinamento avviene tramite API o bus di messaggi che spesso mancano ancora dei controlli di integrità, criptaggio o criptaggio di base. Gli utenti malintenzionati possono intercettare, falsificare o modificare questi messaggi in tempo reale, causando il malfunzionamento dell’intero sistema distribuito. Questa vulnerabilità apre la strada agli attacchi “agent-in-the-middle”, nonché ad altri classici exploit di comunicazione noti nel mondo della sicurezza delle informazioni applicata: riproduzione dei messaggi, spoofing del mittente e downgrade forzato dei protocolli.
Esempio: forzare gli agenti a passare a un protocollo non criptato per iniettare comandi nascosti, con un hijacking efficace del processo decisionale collettivo dell’intero gruppo di agenti.
Errori a catena (ASI08)
Questo rischio descrive come un singolo errore, causato da “allucinazione”, prompt injection o da qualsiasi altro problema tecnico, può propagarsi e amplificarsi in una catena di agenti autonomi. Poiché questi agenti si scambiano le attività senza il coinvolgimento umano, un errore in un collegamento può innescare un effetto domino che porta a una massiccia fusione dell’intera rete. Il problema principale in questo caso è l’assoluta velocità dell’errore: si diffonde molto più velocemente di quanto qualsiasi operatore umano possa tracciare o arrestare.
Esempio: un agente di pianificazione compromesso invia una serie di comandi non sicuri che vengono automaticamente eseguiti dagli agenti a valle, determinando un loop di azioni pericolose replicate nell’intera organizzazione.
Sfruttamento della fiducia uomo-agente (ASI09)
Gli autori degli attacchi sfruttano la natura conversazionale e l’apparente esperienza degli agenti per manipolare gli utenti. L’antropomorfismo porta le persone a riporre eccessiva fiducia nelle raccomandazioni dell’IA e ad approvare le azioni critiche senza pensarci due volte. L’agente agisce come un cattivo consigliere, trasformando l’umano nell’esecutore finale dell’attacco, il che complica una successiva indagine forense.
Esempio: un agente dell’assistenza tecnica compromesso fa riferimento ai numeri dei biglietti effettivi per creare un rapporto con un nuovo assunto, e alla fine convincerlo a fornire le credenziali aziendali.
Rogue agent (ASI10)
Si tratta di agenti dannosi, compromessi o “allucinanti” che esulano dalle funzioni assegnate, operano di nascosto o agiscono come parassiti all’interno del sistema. Una volta perso il controllo, un agente del genere potrebbe iniziare a replicarsi automaticamente, perseguendo la propria agenda nascosta o addirittura in collusione con altri agenti per aggirare le misure di sicurezza. La minaccia principale descritta da ASI10 è l’erosione a lungo termine dell’integrità comportamentale di un sistema in seguito a una violazione o a un’anomalia iniziale.
Esempio: il caso più famigerato riguarda un agente di sviluppo autonomo di Replit che è diventato un rogue agent, ha eliminato il database del cliente primario della rispettiva azienda e quindi ne ha completamente inventato il contenuto facendo sembrare che il problema tecnico fosse stato corretto.
Mitigazione dei rischi nei sistemi di IA degli agenti
Sebbene la natura probabilistica della generazione LLM e la mancanza di separazione tra istruzioni e canali di dati rendano impossibile una sicurezza a prova di proiettile, una serie rigorosa di controlli, che si avvicinano a una strategia Zero Trust, può limitare significativamente i danni quando le cose non vanno per il verso giusto. Ecco le misure più critiche.
Applicare i principi sia di minima autonomia che di privilegio minimo. Limita l’autonomia degli agenti di intelligenza artificiale assegnando attività con guardrail rigorosamente definiti. Assicurarsi che abbiano accesso solo agli strumenti specifici, alle API e ai dati aziendali necessari per lo svolgimento della loro missione. Comporre le autorizzazioni fino al minimo assoluto ove appropriato, ad esempio mantenendo la modalità di sola lettura.
Utilizzare credenziali di breve durata. Emettere token temporanei e chiavi API con un ambito limitato per ogni attività specifica. Questo impedisce a un utente malintenzionato di riutilizzare le credenziali se riesce a compromettere un agente.
Human-in-the-loop obbligatorio per le operazioni critiche. Richiedere una conferma umana esplicita per qualsiasi azione irreversibile o ad alto rischio, come l’autorizzazione di trasferimenti finanziari o l’eliminazione collettiva di dati.
Isolamento dell’esecuzione e controllo del traffico. Eseguire codice e strumenti in ambienti isolati (contenitori o sandbox) con liste consentite rigorose di strumenti e connessioni di rete per prevenire le chiamate in uscita non autorizzate.
Applicazione criteri. Distribuire intent gate per esaminare i piani e gli argomenti di un agente rispetto alle rigide regole di sicurezza prima che vengano attivate.
Convalida e sanificazione di input e output. Utilizzare filtri specializzati e schemi di convalida per verificare la presenza di iniezioni e contenuto dannoso in tutti i prompt e modelli di risposta. Questo deve avvenire in ogni singola fase dell’elaborazione dei dati e ogni volta che i dati vengono trasmessi tra gli agenti.
Registrazione sicura continua. Registrare ogni azione dell’agente e ogni messaggio tra agenti in registri non modificabili. Questi registri sarebbero necessari per eventuali future ispezioni di controllo e indagine forense.
Monitoraggio comportamentale e agenti di watchdog. Distribuire i sistemi automatizzati per individuare le anomalie, come un picco improvviso delle chiamate API, tentativi di autoreplicazione o un agente che si discosta improvvisamente dai propri obiettivi principali. Questo approccio si sovrappone fortemente al monitoraggio richiesto per intercettare sofisticati attacchi di rete “life-off-the-land”. Di conseguenza, le organizzazioni che hanno introdotto XDR ed elaborano la telemetria in un SIEM avranno un vantaggio in questo caso: troveranno molto più facile tenere a bada i propri agenti di intelligenza artificiale.
Controllo della supply chain e SBOM (distinta base del software). Utilizzare solo strumenti selezionati e modelli provenienti da registri di fiducia. Durante lo sviluppo del software, firmare ogni componente, aggiungere le versioni delle dipendenze e ricontrollare ogni aggiornamento.
Analisi statica e dinamica del codice generato. Eseguire la scansione di ogni riga di codice scritta da un agente alla ricerca di vulnerabilità prima dell’esecuzione. Bandire completamente l’utilizzo di funzioni pericolose come eval(). Questi ultimi due suggerimenti dovrebbero già far parte di un flusso di lavoro DevSecOps standard e dovevano essere estesi a tutto il codice scritto dagli agenti di intelligenza artificiale. Eseguire questa operazione manualmente è quasi impossibile, quindi gli strumenti di automazione, come quelli disponibili in Kaspersky Cloud Workload Security, sono consigliati qui.
Protezione delle comunicazioni tra agenti. Garantire l’autenticazione e il criptaggio reciproci su tutti i canali di comunicazione tra gli agenti. Utilizzare le firme digitali per verificare l’integrità dei messaggi.
Kill Switch. Trovare modi per bloccare istantaneamente agenti o strumenti specifici nel momento in cui viene rilevato un comportamento anomalo.
Utilizzo dell’interfaccia utente per la calibrazione attendibile. Utilizzare gli indicatori di rischio visivi e gli avvisi del livello di confidenza per ridurre il rischio che le persone si fidino ciecamente dell’IA.
Formazione utenti. Formare sistematicamente i dipendenti sulle realtà operative dei sistemi basati sull’intelligenza artificiale. Utilizzare esempi su misura per i ruoli lavorativi effettivi per analizzare i rischi specifici dell’IA. Data la velocità con cui questo campo si muove, un video sulla conformità una volta all’anno non basterà: tale formazione dovrebbe essere aggiornata più volte l’anno.
Per gli analisti SOC si consiglia anche il corso Kaspersky Expert Training: Large Language Models Security, che copre le principali minacce per gli LLM e le strategie difensive per contrastarle. Il corso sarebbe utile anche per sviluppatori e i progettisti di intelligenza artificiale che lavorano su implementazioni LLM.
 Consigli
Consigli