 Black Hat 2020
Black Hat 2020
Nessuno vuole spendere milioni di dollari per proteggere un’azienda se il danno effettivo in caso di incidente non supera le diverse migliaia. Ed è altrettanto stupido risparmiare 100 dollari sulla sicurezza se i potenziali danni di una fuga di dati potrebbero ammontare a centinaia di migliaia di dollari. Ma quali informazioni dovreste usare per calcolare il danno approssimativo che un’azienda subirebbe da un cyberincidente e come valutate la probabilità effettiva di un tale incidente? Alla conferenza Black Hat 2020, il professor Wade Baker della Virginia Tech e David Seversky, analista senior del Cyentia Institute, hanno presentato il loro punto di vista sulla valutazione del rischio. Abbiamo trovato le loro argomentazioni degne di ulteriore discussione.
Qualsiasi corso di sicurezza informatica degno di nota insegna che la valutazione del rischio si basa su due fattori principali: la probabilità di un incidente e le sue potenziali perdite. Ma da dove provengono questi dati e, cosa più importante, come vanno interpretati? Dopotutto, valutare le possibili perdite in modo errato porta a conclusioni errate, che portano a strategie di protezione non ottimali.
La media aritmetica è indicativa?
Molte aziende conducono studi sulle perdite finanziarie causate da incidenti di fughe di dati. I loro “risultati principali” sono di solito le medie delle perdite di aziende di dimensioni comparabili. Il risultato è matematicamente valido, e la cifra può fare la sua figura in titoli di giornali accattivanti, ma possiamo davvero fare affidamento su di essa per calcolare i rischi?
Presentare gli stessi dati in un grafico, con le perdite lungo l’asse orizzontale e il numero di incidenti che hanno causato le perdite lungo l’asse verticale, e diventa ovvio che la media aritmetica non è l’indicatore giusto.
Nel 90% degli incidenti, le perdite medie sono inferiori alla media aritmetica.
Se parliamo delle perdite che subirà un business di livello medio, allora ha più senso servirsi di altri indicatori, in particolare, la mediana (il numero che divide il campione in due parti uguali in modo che metà delle cifre riportate siano più alte e metà più basse) e la media geometrica (una media proporzionale). La maggior parte delle aziende subisce proprio queste perdite. La media aritmetica può produrre una cifra molto che può confondere, a causa di un piccolo numero di incidenti periferici con perdite anormalmente elevate.
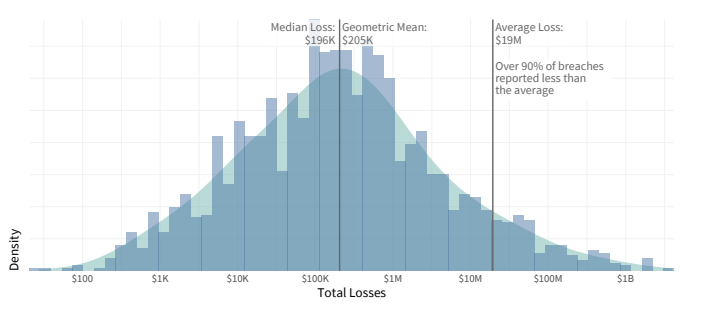
Distribuzione delle perdite derivanti da incidenti di fughe di dati. Fonte
Costo medio di un registro di fughe di dati
Un altro esempio di “media” discutibile deriva dal metodo di calcolo delle perdite derivanti da fughe di dati, moltiplicando il numero di dati interessati per l’importo medio dei danni derivanti dalla perdita di un solo dato. La pratica ha dimostrato che questo metodo sottovaluta le perdite di piccoli incidenti e sovrastima gravemente le perdite di quelle di grandi dimensioni.
Ecco un esempio: qualche tempo fa, si è diffusa una notizia su molti siti di analisi, sostenendo che i servizi cloud mal configurati erano costati alle aziende quasi 5 mila miliardi di dollari. Se si fa una ricerca da dove proviene questa cifra astronomica, diventa chiaro che la cifra di 5 mila miliardi di dollari deriva semplicemente dalla moltiplicazione del numero di dati “trapelati” per i danni medi della perdita di un solo dato (150 dollari). Quest’ultima cifra proviene dallo studio del Ponemon Institute sul costo di una violazione di dati del 2019.
Tuttavia, la storia dovrebbe essere accompagnata da diversi avvertimenti. Innanzitutto, lo studio non ha tenuto conto di tutti gli incidenti. In secondo luogo, anche considerando solo il campione utilizzato, la media aritmetica non dà un’idea chiara delle perdite: sono stati presi in considerazione solo i casi la cui perdita causerebbe danni inferiori a 10.000 dollari e superiori a 1 centesimo. Inoltre, dalla metodologia dello studio risulta chiaro che la media non è valida per gli incidenti in cui sono stati colpiti più di 100.000 record. Pertanto, moltiplicare per 150 il numero totale di record che sono trapelati a causa di servizi cloud configurati in modo non corretto è stato fondamentalmente sbagliato.
Se questo metodo deve produrre una vera valutazione del rischio, deve includere un altro indicatore della probabilità di perdite a seconda della scala dell’incidente. Tale indicatore dovrebbe essere approssimativamente il seguente:
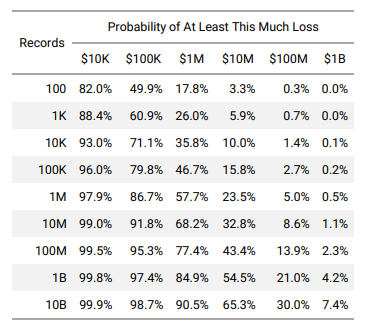
Interconnessione tra la probabilità di subire perdite e il numero di record interessati dall’incidente. Fonte
L’effetto ripple
Un altro fattore spesso trascurato nel calcolo del costo di un incidente è che le moderne fughe di dati incidono sugli interessi di più di una singola azienda. In molti incidenti, il totale dei danni subiti da aziende terze (partner, contractor e fornitori) supera i danni subiti dall’azienda da cui sono trapelati i dati.
Il numero di tali incidenti aumenta ogni anno; la tendenza generale della “digitalizzazione” non fa che aumentare il livello di interdipendenza tra i processi aziendali delle diverse aziende. Secondo i risultati dello studio Ripples Across the Risk Surface, condotto congiuntamente da RiskRecon e Cyentia Institute, 813 incidenti di questo tipo hanno causato perdite subite da 5.437 imprese. Cioè, per ogni azienda che ha subito una fuga di dati, in media sono state coinvolte nell’incidente più di quattro aziende.
Consigli pratici
Riassumendo, gli esperti che valutano i rischi informatici dovrebbero tenere conto dei seguenti consigli:
- Non fidatevi dei titoli di notizie eclatanti. Anche se molti siti contengono determinate informazioni, non hanno necessariamente ragione. Guardate sempre alla fonte che sostiene l’affermazione e analizzate voi stessi la metodologia dei ricercatori;
- Utilizzate nella vostra valutazione del rischio solo i risultati delle ricerche che avete compreso a fondo;
- Tenete presente che un incidente nella vostra azienda può comportare la perdita di dati per altre aziende. Se si verifica una fuga di dati per colpa vostra, è probabile che le altre parti cerchino di rifarsi in tribunale, aumentando i danni derivanti dall’incidente;
- Allo stesso modo, non dimenticate che partner e contractor possono causare fughe di dati che vi riguardano in incidenti con i quali non avete nulla a che fare.

 Consigli
Consigli