 HuMachine
HuMachine
L’efficacia dei nostri prodotti è dovuta al concetto di HuMachine Intelligence, che è la base di ciò che chiamiamo True Cybersecurity. L’essenza della HuMachine Intelligence è una fusione di tre fattori fondamentali: big data, apprendimento automatico e la competenza dei nostri analisti. Ma cosa c’è dietro queste parole? Proviamo a spiegarlo senza entrare in dettagli tecnici.

Big Data e Threat Intelligence
Il termine big data non dovrebbe essere preso alla lettera, come se si trattasse di una vasta gamma di informazioni conservate da qualche parte. Non è solo un database; si tratta di una combinazione di tecnologie che consentono l’elaborazione istantanea di grandi volumi di dati al fine di estrarre informazioni di threat intelligence. In questo caso, con il termine “data” ci riferiamo a tutti gli oggetti, sia che essi siano innocui, totalmente dannosi o potenzialmente utilizzabili per scopi dannosi. Per quanto ci riguarda, i big data fanno riferimento in primo luogo a una vasta raccolta di oggetti dannosi. In secondo luogo, è compreso Kaspersky Security Network, che si aggiorna continuamente con nuovi oggetti dannosi e dati multiformi su varie cyberminacce provenienti da tutto il mondo. In terzo luogo, con big data ci riferiamo ai vari strumenti di categorizzazione che elaborano i dati.
Una raccolta di oggetti dannosi
Ci dedichiamo alla sicurezza informatica da più di 20 anni, e in tutto questo tempo abbiamo analizzato un gran numero di oggetti. Tutte le informazioni in merito sono conservate al sicuro nei nostri database. E quando parliamo di “oggetti”, ci riferiamo non solo ai file o a parti di codici, ma anche a indirizzi Web, certificati, esecuzione di file log per applicazioni legittime e non. Tutti questi dati non solo vengono catalogati con etichette come “pericoloso” o “sicuro”, ma sono immagazzinate anche informazioni sui rapporti tra gli oggetti: da quale sito web il file è stato scaricato, quali altri file sono stati scaricati dal sito e così via.
Kaspersky Security Network (KSN)
KSN è il nostro servizio di sicurezza su cloud. Una delle sue funzioni è quella di bloccare rapidamente le minacce più recenti per il cliente. Allo stesso tempo, permette e tutti i clienti di partecipare alla crescente sicurezza globale inviando su cloud metadati anonimi sulle minacce rilevate. Studiamo ogni minaccia rilevata da vari punti di vista e aggiungiamo le sue caratteristiche nel nostro database delle minacce. Fatto ciò, i nostri sistemi possono rilevare con precisione non solo quella minaccia, ma anche quelle simili. Quindi, la nostra raccolta riceve dati aggiornati in tempo reale.
Strumenti di categorizzazione
Gli strumenti di categorizzazione sono tecnologie interne che ci consentono di elaborare le informazioni che raccogliamo e registrare i rapporti tra gli oggetti dannosi menzionati precedentemente.
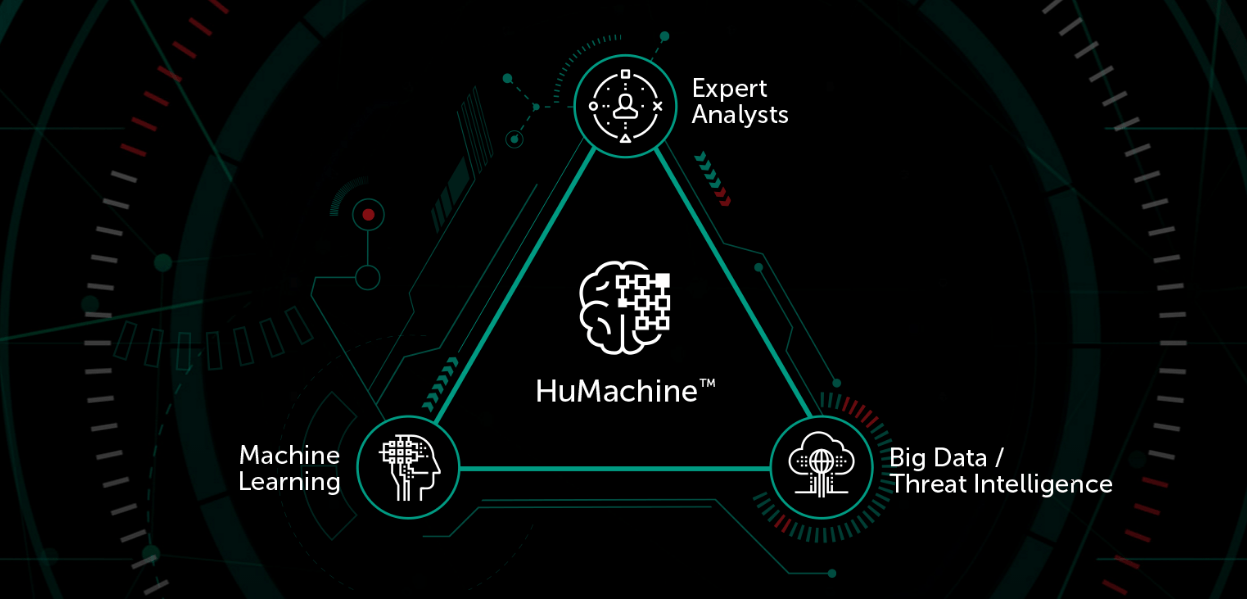
La tecnologia dell’apprendimento automatico
Delineare cosa sia l’apprendimento automatico e come viene utilizzato in Kaspersky Lab non è un compito facile. Innanzitutto va detto che usiamo un approccio multilivello. Gli algoritmi di apprendimento automatico vengono utilizzati in diversi sottosistemi e a diversi livelli.
Rilevamento statico
Ogni giorno i nostri sistemi ricevono centinaia di migliaia di oggetti che hanno bisogno di un’analisi tempestiva e di categorizzazione (etichettare un oggetto come pericoloso o meno). Già più di 10 anni fa sapevamo che non avremmo potuto farcela senza automazione. Il primo compito era capire se un file sospetto assomigliasse a uno dannoso che già avevamo. E qui entrava in gioco l’apprendimento automatico: abbiamo creato un’applicazione che analizzava tutti i nostri dati salvati e, quando veniva aggiunto un nuovo file, i nostri analisti venivano informati su quale fosse l’oggetto più simile al nuovo arrivato.
È divenuto subito chiaro che sapere se un oggetto fosse simile ad altri dannosi non era abbastanza. Avevamo bisogno di una tecnologia che permettesse al sistema di dare un verdetto in maniera indipendente. Così abbiamo costruito una tecnologia basata su alberi di decisione. Addestrata sulla nostra vasta raccolta di oggetti dannosi, la tecnologia rilevava una serie di criteri, specifiche combinazioni che potevano servire come indicatori che definiscono senza ambiguità un nuovo file come pericoloso. Mentre analizza un file, un modello matematico “chiede” al motore antivirus delle domande come queste:
- Il file è di dimensioni superiori a 100 kilobyte?
- In caso affermativo, è questo un file compresso?
- Se non lo è, i nomi delle sue sezioni sono qualcosa che un umano sceglierebbe o senza senso?
- Se è la prima, allora…
E la lista delle domande va avanti.
Dopo aver risposto a tutte queste domande, il motore antivirus riceve un verdetto dal modello matematico. Il verdetto può essere “il file è pulito” o “il file è pericoloso.”
Modello matematico comportamentale
Seguendo il nostro principio di sicurezza multilivello, i nostri modelli matematici vengono anche utilizzati per il rilevamento dinamico. In effetti, un modello matematico è in grado di analizzare il comportamento di un file eseguibile proprio durante la sua esecuzione. È possibile costruire e formare il modello secondo gli stessi principi applicati ai modelli matematici di rilevamento statico, utilizzando invece i log file di esecuzione come “materiali di allenamento”. Tuttavia, c’è una grande differenza; in condizioni reali, non possiamo permetterci di aspettare finché il codice termini l’esecuzione. La decisione dovrebbe essere presa dopo aver analizzato un minimo di azioni. Attualmente, un progetto pilota di questa tecnologia, basata sull’apprendimento profondo, sta dando ottimi risultati.
Competenza umana
Gli esperti in apprendimento automatico concordano sul fatto che non importa quanto intelligente sia un modello matematico, un essere umano sarà sempre in grado di superarlo, soprattutto se la persona è creativa e può dare un’occhiata a come funziona la tecnologia, o se c’è tempo a disposizione per eseguire numerosi test ed esperimenti. Per questo motivo, prima di tutto, ogni parte del modello deve essere aggiornabile; in secondo luogo, l’infrastruttura deve funzionare perfettamente; e terzo, l’essere umano deve controllare il robot. Ecco qui sono tutti e tre i casi.
Ricerca anti-malware
Circa 20 anni fa, la nostra squadra di Anti-Malware Research (AMR) operava senza l’ausilio di sistemi automatici. Oggi, la maggior parte delle minacce vengono rilevate da sistemi formati dai nostri ricercatori. In alcuni casi, il sistema non può dare un verdetto inequivocabile oppure pensa che l’oggetto sia dannoso, ma non può ricollegarlo a nessuna famiglia conosciuta. Quindi, il sistema invia un avvertimento ad un analista AMR in servizio, fornendo una serie completa di indicatori in modo che l’analista possa prendere la decisione finale.
Detection Methods Analysis Group
All’interno al nostro AMR c’è un gruppo di ricerca specifico chiamato Detection Methods Analysis Group, che è stato creato nel 2007 per lavorare specificamente sui nostri sistemi di apprendimento automatico. Attualmente, solo il capo del dipartimento è un analista esperto dei virus. Gli altri dipendenti sono puri data scientist.
Global Research and Analysis Team (GReAT)
Ultimo ma non meno importante, parliamo del nostro Global Research and Analysis Team (GReAT). I ricercatori di questa squadra indagano le minacce più complesse: APT, campagne di cyberspionaggio, i maggiori focolai di malware, ransomware e le tendenze cybercriminali nascoste ma presenti in tutto il mondo. La loro competenza unica sulle tecniche, gli strumenti e gli schemi di cyberattacchi ci consente di sviluppare nuovi metodi di protezione che possono fermare anche gli attacchi più complessi.
Non abbiamo ancora parlato nemmeno della metà delle tecnologie e dei reparti coinvolti nello sviluppo delle nostre soluzioni. Molti altri esperti e diversi metodi di appprendimento automatico lavorano insieme per proteggervi in modo ottimale, ma volevamo illustrare nello specifico il principio di HuMachine Intelligence.

 Consigli
Consigli